Semester 3 - Data Mining (Week 1-4)
Data Mining
-
Data Mining, also known as Knowledge Discovery in Database (KDD), is a process used to extract valuable information from large sets of data.
- It involves various aspects such as:
-
Data Types: Includes relational, transactional, data warehouse data, and complex data types like time-series, sequences, data streams, spatiotemporal data, multimedia data, text data, graphs, social networks, and Web data.
-
Knowledge Mined: Involves discovering patterns, associations, correlations, and causal structures.
-
Technologies Used: Incorporates machine learning, statistics, pattern recognition, neural networks, and visualization.
-
Applications: Extensively used in various fields such as business, science, engineering, and healthcare.
-
- Major challenges
- scalability,
- handling different types of attributes,
- dealing with noisy data, and
- developing incremental clustering algorithms.
Summarize about the steps in Knowledge Discovery Process
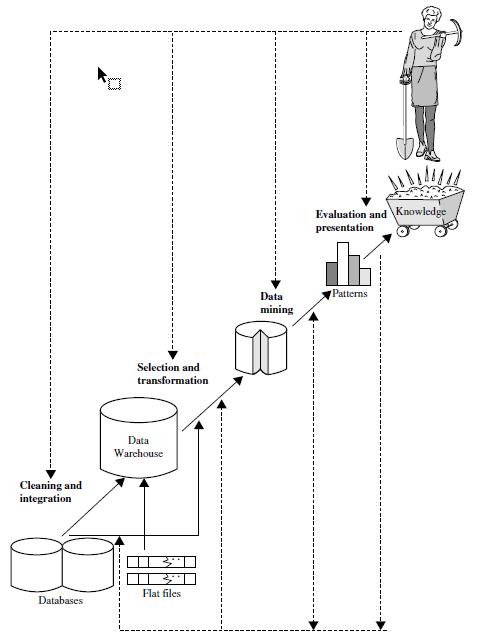
Knowledge Discovery Process
- Data Cleaning: Remove noise and inconsistent data.
- Data Integration: Combine multiple data sources.
- Data Selection: Data relevant to the analysis task are retrieved from the database.
- Data Transformation: Consolidate data into mining-friendly formats.
- Data Mining: Apply intelligent methods to uncover patterns.
- Pattern Evaluation: Identify valuable patterns via interestingness measures.
- Knowledge Presentation: Visualization and knowledge representation techniques are used to present the mined knowledge.
Briefly summarize about “Transactional Data”
- Refers to the data that records an exchange, agreement or transfer between entities.
- Captures every system event detail.
- Examples: order delivery, purchase orders, invoices.
Explain different Data Mining Functionalities
- Characterization/Discrimination: Summarize and contrast data.
- Association/Correlation: Find relationships in data.
- Classification/Regression: Create data models and predict labels.
- Cluster Analysis: Group data into clusters.
- Outlier Analysis: Identify non-compliant data.
- Trend/Evolution: Describe trends over time.
What is a “Data Warehouse”? Explain the importance of DW in data mining field.
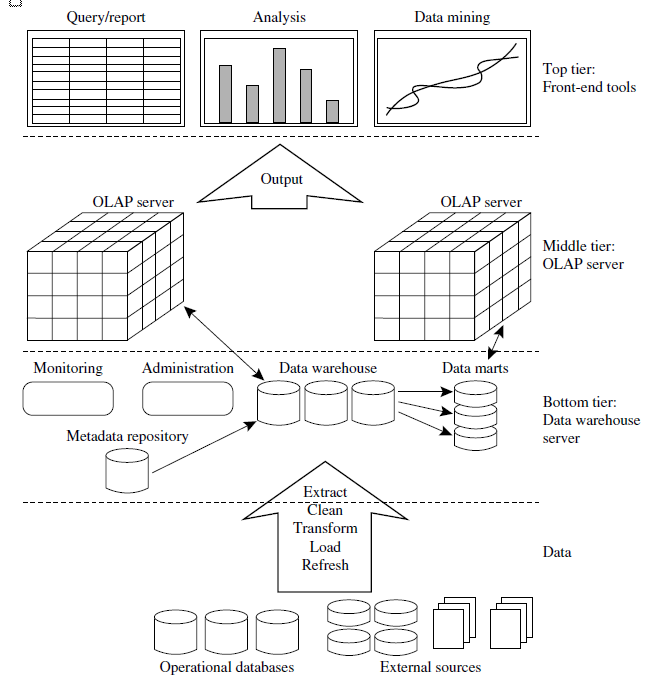
Three tier data warehousing architecture
Data Warehouse
- Collects and manages data from various sources.
- Enables strategic data use through a mix of technologies and components.
- Offers consistent business view, irrespective of data source.
- Acts as electronic storage for large information volumes.
- Designed for query and analysis rather than transaction processing.
- Transforms data into information for user analysis.
Important reasons for using Data warehouse
- Integrates many sources of data and helps to decrease stress on a production system.
- Optimized Data for reading access and consecutive disk scans.
- Data Warehouse helps to protect Data from the source system upgrades.
- Allows users to perform master Data Management.
- Improve data quality in source systems.
What are the issues faced in Data mining?
- Mining Methodology: Managing diverse data types, noise, uncertainty, scalability.
- User Interaction: Maintaining simplicity, transparency, and user engagement.
- Efficiency and Scalability: Ensuring fast, scalable data processing.
- Diversity of Database Types: Handling various data types and sources.
- Data Mining and Society: Navigating information misuse, privacy, security.



