Semester 3 - Data Mining (Week 5-7)
Explain the categorization of visualization methods?
Data Visualization
- Graphically represents data for clear communication.
- Used for reporting, managing operations, tracking tasks, and discovering data relationships.
Visualization Techniques
![]()
A Pixel-oriented visualization
- Pixel-Oriented: Uses color-shaded pixels to reflect data values and analyze correlations.
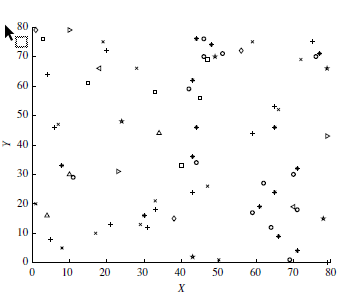
A Geometric projection visualization
- Geometric Projection: Visualizes geometric transformations and projections of multidimensional data.

A Chernoff faces (Icon-based) visualization
- Icon-Based: Uses icons, like Chernoff faces, to represent multidimensional data.
- Chernoff Faces (Icon-Based)
- Cartoon human faces representing up to 18 variables of multidimensional data.
- Chernoff Faces (Icon-Based)

A Tree map (Hierarchial) visualization
- Hierarchical: Partitions dimensions into subsets visualized hierarchically. Methods include Info cube and screen filling method, Tree maps and Infocube.
Visualizing Complex Data and Relations
- Techniques now include non-numeric data like text and social networks.
- Tag clouds visualize statistics of user-generated tags.
- Methods exist for visualizing relationships like social networks.
What is Data Quality?
- Defined in terms of accuracy, completeness, consistency, timeliness, believability, and interpretability.
- Quality is assessed based on the intended use of the data.
Factors Affecting Data Quality
- Poorly designed data entry forms with many optional fields.
- Human and deliberate errors.
- Data decay and inconsistencies.
- Instrumentation and system errors.
- Inadequate data usage.
Explain about Data Preprocessing
- Involves cleaning, integrating, reducing, and transforming data.
- Cleaning fills in missing values, smooths noise, identifies outliers, and corrects inconsistencies.
- Integration merges data from multiple sources.
- Reduction minimizes data size while preserving information.
- Transformation adjusts data for optimal mining.
Summarize Data Cleaning
- Involves filling missing values, smoothing noise, identifying outliers, and correcting inconsistencies.
- Typically an iterative two-step process: discrepancy detection and data transformation.
What is Integration of Data?
- Combines data from different sources into one place.
- Involves sorting out differences in meaning, managing data about data, checking relationships, finding and handling duplicate data and conflicts.
Define Reduction and Data Transformation
- Part of data mining process.
- Aims to decrease data volume while maintaining similar analytical outcomes.
- Simplifies data for easier understanding and interpretation.
- Techniques include reducing dimensions, reducing number of data points, and data compression.
What is Euclidean Distance?
- Measures straight line distance between two points in a space.
- Derived from Pythagoras’ theorem, used in data mining and machine learning.
- Calculated using square root of sum of squares of differences in each dimension.
- In 2D space, Euclidean distance between points (x1, y1) and (x2, y2) is sqrt((x2-x1)² + (y2-y1)²).
- In 3D space, it extends to sqrt((x2-x1)² + (y2-y1)² + (z2-z1)²).
- For higher dimensions, it’s sqrt(Σ(xi-yi)²), summing over all dimensions.
Define Different Distance Measures
- Euclidean Distance: Straight line distance between two points.
- Manhattan Distance: Distance between points along orthogonal axes (grid-based).
- Chebyshev Distance: Maximum absolute distance in one dimension.
- Minkowski Distance: Generalized metric distance measure with power p.
- Hamming Distance: Minimum substitutions to change one string into another.
- Mahalanobis Distance: Distance between a point and a distribution.
Data Similarity and Dissimilarity
- Data similarity measures the likeness between two data objects.
- It is subjective and defined based on the context.
- Typically represented as a distance, with smaller distances indicating higher similarity.
- Dissimilarity refers to the unlikeness or differences between data objects.
Define Data Visualization
- Graphical representation of information and data.
- Utilizes various visual tools like charts, graphs, and infographics.
- Facilitates clear and efficient communication of information.
- Enables quick analysis and exploration of large data sets for decision-making.
Data Discretization
- Converts continuous data to discrete form.
- Improves data understandability and interpretability.
- Enhances machine learning model performance.
- Methods include binning, histogram analysis, decision trees, and clustering.



